No New Work
Message boards : Number crunching : No New Work
| Author | Message |
|---|---|
|
Destroyer_Kahn Send message Joined: 13 Oct 05 Posts: 9 Credit: 63,540 RAC: 0 |
I haven't gotten any new work from Rosetta for about a month. Everything seems to be functioning normally - no units in Work, and when I check messages it doesn't even look like it is requesting anymore work. Any ideas? Other BOINC stuff seems to be perfectly fine (SETI, etc.) |
 Tern TernSend message Joined: 25 Oct 05 Posts: 576 Credit: 4,702,007 RAC: 0 |
You have 12 results that were never returned and passed deadline; you have 12 results currently "in progress" according to the server, which will be passing deadline shortly. Please do this: Quit BOINC completely (file/exit). Re-launch BOINC Manager. Go to the Projects tab, select Rosetta, and hit "Update". Wait for "Scheduler request pending" to go away. (Verify that Status does _not_ say "suspended by user" or "Won't get new work", also...) Go to the Messages tab, copy all messages. Return here and paste all the messages in. Something's definitely wrong, but can't tell from this end what it is. 
|
|
Destroyer_Kahn Send message Joined: 13 Oct 05 Posts: 9 Credit: 63,540 RAC: 0 |
I did as you said. Here are the messages: 12/22/2005 4:46:25 PM|rosetta@home|Computer ID: 20583; location: home; project prefs: default 12/22/2005 4:46:37 PM|rosetta@home|Sending scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi 12/22/2005 4:46:37 PM|rosetta@home|Reason: Requested by user 12/22/2005 4:46:37 PM|rosetta@home|Note: not requesting new work or reporting results 12/22/2005 4:46:42 PM|rosetta@home|Scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi succeeded Note that after I hit Update I got a "Communication Deferred" message, after the timer elapsed it just went away and no new messages. I do NOT have "Suspend" or "No New Work" turned on (apparent since they show up as clickable buttons on the Projects tab. Any ideas? |
|
Tern Send message Joined: 25 Oct 05 Posts: 576 Credit: 4,702,007 RAC: 0 |
12/22/2005 4:46:37 PM|rosetta@home|Note: not requesting new work or reporting results Many... any _useful_ ones... maybe. There should have been more messages in there, showing what SETI was doing. If you still have those handy, "copy all" and paste would help. If any of those said anything about "computer is overcommitted", then I may have some clues. Please go to "Your Account", "View Computers", and copy the bottom part of that page and paste it in here. Here's what I'm looking for, from mine: % of time BOINC client is running 99.6162 % While BOINC running, % of time host has an Internet connection -100 % While BOINC running, % of time work is allowed 99.9899 % Average CPU efficiency 0.990981 Result duration correction factor 2.089648 I'm suspecting that one of these that SHOULD be close to 100%, has somehow gotten set very low. If so, I can tell you how to fix it. If not, we'll have to look at long term debts. I'm assuming SETI is still running okay for you?
|
|
Destroyer_Kahn Send message Joined: 13 Oct 05 Posts: 9 Credit: 63,540 RAC: 0 |
Ok, here are all messages after restarting: 12/22/2005 7:06:38 PM||Starting BOINC client version 5.2.13 for windows_intelx86 12/22/2005 7:06:38 PM||libcurl/7.14.0 OpenSSL/0.9.8 zlib/1.2.3 12/22/2005 7:06:38 PM||Data directory: C:Program FilesBOINC 12/22/2005 7:06:38 PM||Processor: 2 GenuineIntel Intel(R) Pentium(R) 4 CPU 3.00GHz 12/22/2005 7:06:38 PM||Memory: 2.00 GB physical, 3.35 GB virtual 12/22/2005 7:06:38 PM||Disk: 149.01 GB total, 77.41 GB free 12/22/2005 7:06:38 PM|rosetta@home|Computer ID: 20583; location: home; project prefs: default 12/22/2005 7:06:38 PM|climateprediction.net|Computer ID: 180131; location: home; project prefs: default 12/22/2005 7:06:38 PM|Einstein@Home|Computer ID: 253314; location: home; project prefs: default 12/22/2005 7:06:38 PM|LHC@home|Computer ID: 73961; location: home; project prefs: default 12/22/2005 7:06:38 PM|Predictor @ Home|Computer ID: 175489; location: home; project prefs: default 12/22/2005 7:06:38 PM|SETI@home|Computer ID: 1688162; location: home; project prefs: default 12/22/2005 7:06:38 PM||General prefs: from Predictor @ Home (last modified 2005-10-13 18:18:50) 12/22/2005 7:06:38 PM||General prefs: no separate prefs for home; using your defaults 12/22/2005 7:06:39 PM||Remote control not allowed; using loopback address 12/22/2005 7:06:39 PM|climateprediction.net|Deferring computation for result 17i3_300076964_1 12/22/2005 7:06:39 PM|climateprediction.net|Deferring computation for result sulphur_dqwx_000641409_0 12/22/2005 7:06:39 PM|SETI@home|Resuming computation for result 18mr05aa.19527.14736.828400.237_1 using setiathome version 418 12/22/2005 7:06:39 PM|SETI@home|Resuming computation for result 06se04aa.18035.28754.829832.230_0 using setiathome version 418 12/22/2005 7:06:39 PM|LHC@home|Sending scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi 12/22/2005 7:06:39 PM|LHC@home|Reason: To fetch work 12/22/2005 7:06:39 PM|LHC@home|Requesting 17280 seconds of new work 12/22/2005 7:06:45 PM|LHC@home|Scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi succeeded 12/22/2005 7:06:45 PM|LHC@home|No work from project 12/22/2005 7:06:47 PM||request_reschedule_cpus: project op 12/22/2005 7:06:50 PM|rosetta@home|Sending scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi 12/22/2005 7:06:50 PM|rosetta@home|Reason: Requested by user 12/22/2005 7:06:50 PM|rosetta@home|Note: not requesting new work or reporting results 12/22/2005 7:06:55 PM|rosetta@home|Scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi succeeded 12/22/2005 7:07:45 PM|LHC@home|Fetching master file 12/22/2005 7:07:50 PM|LHC@home|Master file download succeeded 12/22/2005 7:07:55 PM|LHC@home|Sending scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi 12/22/2005 7:07:55 PM|LHC@home|Reason: To fetch work 12/22/2005 7:07:55 PM|LHC@home|Requesting 17280 seconds of new work 12/22/2005 7:08:00 PM|LHC@home|Scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi succeeded 12/22/2005 7:08:00 PM|LHC@home|No work from project 12/22/2005 7:09:01 PM|LHC@home|Sending scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi 12/22/2005 7:09:01 PM|LHC@home|Reason: To fetch work 12/22/2005 7:09:01 PM|LHC@home|Requesting 17280 seconds of new work 12/22/2005 7:09:06 PM|LHC@home|Scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi succeeded 12/22/2005 7:09:06 PM|LHC@home|No work from project 12/22/2005 7:10:06 PM|LHC@home|Sending scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi 12/22/2005 7:10:06 PM|LHC@home|Reason: To fetch work 12/22/2005 7:10:06 PM|LHC@home|Requesting 17280 seconds of new work 12/22/2005 7:10:11 PM|LHC@home|Scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi succeeded 12/22/2005 7:10:11 PM|LHC@home|No work from project 12/22/2005 7:11:12 PM|LHC@home|Sending scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi 12/22/2005 7:11:12 PM|LHC@home|Reason: To fetch work 12/22/2005 7:11:12 PM|LHC@home|Requesting 17280 seconds of new work Resource shares: Rosetta = 3.39% (8) Climateprediction = 3.39% (8) LHC = 16.95% (40) Einstein = 16.95% (40) Predictor = 16.95% (40) Seti = 42.37% (100) Only Seti and Climateprediction are getting work. LHC is reporting no work from project. But Climateprediction is set to 3.39% also, so that doesn't seem like the problem, or is it? |
|
Destroyer_Kahn Send message Joined: 13 Oct 05 Posts: 9 Credit: 63,540 RAC: 0 |
Oh, and info from the view computers screen: % of time BOINC client is running 85.9459 % While BOINC running, % of time host has an Internet connection 99.9684 % While BOINC running, % of time work is allowed 98.707 % Average CPU efficiency 0.970953 Result duration correction factor 1 |
|
Destroyer_Kahn Send message Joined: 13 Oct 05 Posts: 9 Credit: 63,540 RAC: 0 |
And yes, seti is running great! |
|
Yeti Send message Joined: 2 Nov 05 Posts: 45 Credit: 16,195,236 RAC: 0 |
12/22/2005 7:06:50 PM|rosetta@home|Sending scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi 12/22/2005 7:06:50 PM|rosetta@home|Reason: Requested by user 12/22/2005 7:06:50 PM|rosetta@home|Note: not requesting new work or reporting results 12/22/2005 7:06:55 PM|rosetta@home|Scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi succeeded All seems to be fine ! The ResourceShare on your client says, that it is not time for Rosetta to get work; you can hit the update-button as often you want, you won't get new work from Rosetta. You have given Rosetta 3% ResourceShare. Your possibilies are:
 Supporting BOINC, a great concept ! |
|
Destroyer_Kahn Send message Joined: 13 Oct 05 Posts: 9 Credit: 63,540 RAC: 0 |
Ok, I suspended all other work (seti, etc). Updated rosetta, got this: 12/22/2005 7:11:17 PM|LHC@home|Scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi succeeded 12/22/2005 7:11:17 PM|LHC@home|No work from project 12/22/2005 7:12:17 PM|LHC@home|Sending scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi 12/22/2005 7:12:17 PM|LHC@home|Reason: To fetch work 12/22/2005 7:12:17 PM|LHC@home|Requesting 17280 seconds of new work 12/22/2005 7:12:32 PM|LHC@home|Scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi succeeded 12/22/2005 7:12:32 PM|LHC@home|No work from project 12/22/2005 7:14:43 PM|LHC@home|Sending scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi 12/22/2005 7:14:43 PM|LHC@home|Reason: To fetch work 12/22/2005 7:14:43 PM|LHC@home|Requesting 17280 seconds of new work 12/22/2005 7:14:48 PM|LHC@home|Scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi succeeded 12/22/2005 7:14:48 PM|LHC@home|No work from project 12/22/2005 7:16:23 PM|LHC@home|Sending scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi 12/22/2005 7:16:23 PM|LHC@home|Reason: To fetch work 12/22/2005 7:16:23 PM|LHC@home|Requesting 17280 seconds of new work 12/22/2005 7:16:28 PM|LHC@home|Scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi succeeded 12/22/2005 7:16:28 PM|LHC@home|No work from project 12/22/2005 7:29:49 PM|LHC@home|Sending scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi 12/22/2005 7:29:49 PM|LHC@home|Reason: To fetch work 12/22/2005 7:29:49 PM|LHC@home|Requesting 17280 seconds of new work 12/22/2005 7:29:54 PM|LHC@home|Scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi succeeded 12/22/2005 7:29:54 PM|LHC@home|No work from project 12/22/2005 7:33:15 PM|LHC@home|Sending scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi 12/22/2005 7:33:15 PM|LHC@home|Reason: To fetch work 12/22/2005 7:33:15 PM|LHC@home|Requesting 17280 seconds of new work 12/22/2005 7:33:20 PM||request_reschedule_cpus: project op 12/22/2005 7:33:20 PM||Suspending work fetch because computer is overcommitted. 12/22/2005 7:33:20 PM|LHC@home|Scheduler request to http://lhcathome-sched1.cern.ch/scheduler/cgi succeeded 12/22/2005 7:33:20 PM|LHC@home|No work from project 12/22/2005 7:33:23 PM||request_reschedule_cpus: project op 12/22/2005 7:33:23 PM||Allowing work fetch again. 12/22/2005 7:33:36 PM||request_reschedule_cpus: project op 12/22/2005 7:33:41 PM||request_reschedule_cpus: project op 12/22/2005 7:33:51 PM||request_reschedule_cpus: project op 12/22/2005 7:33:53 PM||request_reschedule_cpus: project op 12/22/2005 7:33:57 PM||request_reschedule_cpus: project op 12/22/2005 7:33:58 PM||request_reschedule_cpus: project op 12/22/2005 7:34:37 PM||request_reschedule_cpus: project op 12/22/2005 7:34:38 PM|climateprediction.net|Restarting result 17i3_300076964_1 using hadsm3 version 413 12/22/2005 7:34:38 PM|climateprediction.net|Restarting result sulphur_dqwx_000641409_0 using sulphur_cycle version 419 12/22/2005 7:34:38 PM|SETI@home|Pausing result 18mr05aa.19527.14736.828400.237_1 (removed from memory) 12/22/2005 7:34:38 PM|SETI@home|Pausing result 06se04aa.18035.28754.829832.230_0 (removed from memory) 12/22/2005 7:34:39 PM||request_reschedule_cpus: process exited 12/22/2005 7:34:49 PM||request_reschedule_cpus: project op 12/22/2005 7:34:49 PM|climateprediction.net|Pausing result 17i3_300076964_1 (removed from memory) 12/22/2005 7:34:49 PM|climateprediction.net|Pausing result sulphur_dqwx_000641409_0 (removed from memory) 12/22/2005 7:34:50 PM|rosetta@home|Sending scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi 12/22/2005 7:34:50 PM|rosetta@home|Reason: To fetch work 12/22/2005 7:34:50 PM|rosetta@home|Requesting 17280 seconds of new work 12/22/2005 7:34:51 PM||request_reschedule_cpus: process exited 12/22/2005 7:34:51 PM||request_reschedule_cpus: project op 12/22/2005 7:34:53 PM||request_reschedule_cpus: project op 12/22/2005 7:34:55 PM||request_reschedule_cpus: project op 12/22/2005 7:34:55 PM|rosetta@home|Scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi succeeded 12/22/2005 7:34:55 PM|rosetta@home|No work from project 12/22/2005 7:34:58 PM||request_reschedule_cpus: project op 12/22/2005 7:35:01 PM|rosetta@home|Sending scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi 12/22/2005 7:35:01 PM|rosetta@home|Reason: Requested by user 12/22/2005 7:35:01 PM|rosetta@home|Requesting 17280 seconds of new work 12/22/2005 7:35:06 PM|rosetta@home|Scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi succeeded 12/22/2005 7:35:48 PM||request_reschedule_cpus: project op 12/22/2005 7:35:51 PM|rosetta@home|Sending scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi 12/22/2005 7:35:51 PM|rosetta@home|Reason: Requested by user 12/22/2005 7:35:51 PM|rosetta@home|Requesting 17280 seconds of new work 12/22/2005 7:35:56 PM|rosetta@home|Scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi succeeded 12/22/2005 7:40:01 PM|rosetta@home|Sending scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi 12/22/2005 7:40:01 PM|rosetta@home|Reason: To fetch work 12/22/2005 7:40:01 PM|rosetta@home|Requesting 17280 seconds of new work 12/22/2005 7:40:06 PM|rosetta@home|Scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi succeeded 12/22/2005 7:40:08 PM|rosetta@home|Started download of rosetta_4.81_windows_intelx86.exe 12/22/2005 7:40:08 PM|rosetta@home|Started download of 1hz6A.psipred_ss2.gz 12/22/2005 7:40:10 PM|rosetta@home|Finished download of 1hz6A.psipred_ss2.gz 12/22/2005 7:40:10 PM|rosetta@home|Throughput 3707 bytes/sec 12/22/2005 7:40:10 PM|rosetta@home|Started download of 1hz6.pdb.gz 12/22/2005 7:40:11 PM|rosetta@home|Finished download of 1hz6.pdb.gz 12/22/2005 7:40:11 PM|rosetta@home|Throughput 17363 bytes/sec 12/22/2005 7:40:11 PM|rosetta@home|Started download of 1hz6A.fasta 12/22/2005 7:40:12 PM|rosetta@home|Finished download of 1hz6A.fasta 12/22/2005 7:40:12 PM|rosetta@home|Throughput 218 bytes/sec 12/22/2005 7:40:12 PM|rosetta@home|Started download of aa1hz6A09_05.200_v1_3.gz 12/22/2005 7:40:21 PM|rosetta@home|Finished download of aa1hz6A09_05.200_v1_3.gz 12/22/2005 7:40:21 PM|rosetta@home|Throughput 170466 bytes/sec 12/22/2005 7:40:21 PM|rosetta@home|Started download of aa1hz6A03_05.200_v1_3.gz 12/22/2005 7:40:22 PM|rosetta@home|Finished download of rosetta_4.81_windows_intelx86.exe 12/22/2005 7:40:22 PM|rosetta@home|Throughput 370236 bytes/sec 12/22/2005 7:40:22 PM|rosetta@home|Started download of 1hz6.top7_lowenergy.cst 12/22/2005 7:40:23 PM|rosetta@home|Finished download of aa1hz6A03_05.200_v1_3.gz 12/22/2005 7:40:23 PM|rosetta@home|Throughput 261710 bytes/sec 12/22/2005 7:40:23 PM|rosetta@home|Finished download of 1hz6.top7_lowenergy.cst 12/22/2005 7:40:23 PM|rosetta@home|Throughput 25156 bytes/sec 12/22/2005 7:40:24 PM||request_reschedule_cpus: files downloaded 12/22/2005 7:40:24 PM|rosetta@home|Starting result 1hz6A_topology_sample_207_14118_7 using rosetta version 481 12/22/2005 7:40:49 PM|rosetta@home|Unrecoverable error for result 1hz6A_topology_sample_207_14118_7 ( - exit code -1073741819 (0xc0000005)) 12/22/2005 7:40:49 PM||request_reschedule_cpus: process exited 12/22/2005 7:40:49 PM|rosetta@home|Computation for result 1hz6A_topology_sample_207_14118_7 finished 12/22/2005 7:44:12 PM|rosetta@home|Sending scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi 12/22/2005 7:44:12 PM|rosetta@home|Reason: To report results 12/22/2005 7:44:12 PM|rosetta@home|Requesting 17280 seconds of new work, and reporting 1 results 12/22/2005 7:44:17 PM|rosetta@home|Scheduler request to https://boinc.bakerlab.org/rosetta_cgi/cgi succeeded 12/22/2005 7:44:19 PM|rosetta@home|Started download of 1ogw.top7_lowenergy.cst 12/22/2005 7:44:19 PM|rosetta@home|Started download of 1ogw.pdb.gz 12/22/2005 7:44:21 PM|rosetta@home|Finished download of 1ogw.top7_lowenergy.cst 12/22/2005 7:44:21 PM|rosetta@home|Throughput 51423 bytes/sec 12/22/2005 7:44:21 PM|rosetta@home|Finished download of 1ogw.pdb.gz 12/22/2005 7:44:21 PM|rosetta@home|Throughput 27144 bytes/sec 12/22/2005 7:44:21 PM|rosetta@home|Started download of aa1ogw_09_05.200_v1_3.gz 12/22/2005 7:44:21 PM|rosetta@home|Started download of 1ogw_.psipred_ss2.gz 12/22/2005 7:44:23 PM|rosetta@home|Finished download of 1ogw_.psipred_ss2.gz 12/22/2005 7:44:23 PM|rosetta@home|Throughput 4472 bytes/sec 12/22/2005 7:44:23 PM|rosetta@home|Started download of aa1ogw_03_05.200_v1_3.gz 12/22/2005 7:44:27 PM|rosetta@home|Finished download of aa1ogw_03_05.200_v1_3.gz 12/22/2005 7:44:27 PM|rosetta@home|Throughput 191217 bytes/sec 12/22/2005 7:44:27 PM|rosetta@home|Started download of 1ogw_.fasta 12/22/2005 7:44:28 PM|rosetta@home|Finished download of aa1ogw_09_05.200_v1_3.gz 12/22/2005 7:44:28 PM|rosetta@home|Throughput 315699 bytes/sec 12/22/2005 7:44:28 PM|rosetta@home|Finished download of 1ogw_.fasta 12/22/2005 7:44:28 PM|rosetta@home|Throughput 403 bytes/sec 12/22/2005 7:44:29 PM||request_reschedule_cpus: files downloaded 12/22/2005 7:44:29 PM|rosetta@home|Starting result 1ogw__topology_sample_207_4499_7 using rosetta version 481 12/22/2005 7:44:57 PM|rosetta@home|Unrecoverable error for result 1ogw__topology_sample_207_4499_7 ( - exit code -1073741819 (0xc0000005)) 12/22/2005 7:44:57 PM||request_reschedule_cpus: process exited 12/22/2005 7:44:57 PM|rosetta@home|Computation for result 1ogw__topology_sample_207_4499_7 finished Anyways, now I have rosetta work running. Why did this happen? How do I keep it running right? Suggestions please. This problem did NOT start immediately after I adjusted my resource shares. It ran fine for awhile. |
|
Tern Send message Joined: 25 Oct 05 Posts: 576 Credit: 4,702,007 RAC: 0 |
This is all making more sense now; I thought SETI was your only other project! Hit "Suspend" on LHC. You can resume it when they have work. If that doesn't fix it, you need to download a program called BOINCDV (for "debt viewer"). Google should work, or it's available off of SETI's "other software" links page, or if you can't find it, I can dig up a URL around here for you. That program will show you the "long term debts" for all of the projects, and if any of those are really "extreme" (say over 72,000) you might want to "reset debts" using that utility. But... I don't think there is a real problem here, just because your resource share for Rosetta is so low; it's only going to get Rosetta work if nothing else is available, or maybe once a month just to satisfy the debt. The reason you have a CPDN result is because if you even asked for 1 _second_ of CPDN, you got several WEEKS worth of work in that "Sulphur" WU. At 4%, you _may_ not even be able to finish it before the deadline, and the deadline is a year away! (As you get close, you may find yourself 'overcommitted', and doing nothing _but_ CPDN, in order to try to make that deadline - for days...) With your resource shares, SETI, Einstein, Predictor, and LHC are the only ones that are going to be consistently getting work, but it's not going to be "regular" for any but SETI. The other three are going to have periods where they get work, and others where nothing happens. As for CPDN and Rosetta... 4% of a month is 1 day... I don't know what happened in the past, that you got a block of Rosetta work and didn't return it on time, and then got another block that's "in progress" on the server, but not on your computer... It looks like in messing with it today, you got a couple more WUs, but your luck is holding - they were two of the "short WUs" from the bad batch that was created yesterday. I really think that short of making your resource shares a little more "equal", the only thing you can do is leave it alone and let it run, and expect CPDN problems in a few months, and deal with the long gaps between working on some projects. I won't say that you are "over attached", as some people happily run even more projects than you do, and you have a fast computer - but, well, maybe you're over attached. CPDN in particular is a monster; hard to drop though, as you've already got time in it. You might think about dropping LHC and Predictor, or even any one of your "40s" and Rosetta. (Hm. On Rosetta board. Saying drop Rosetta. Disregard last sentence.) Or, what _I_ would do - drop Predictor (I'm mad at them) and set the others ALL to "100". EDIT:: You and Yeti both posted while I was typing. Yes, suspending everything else is one way to get Rosetta... but it's "tricking" the scheduler, by removing everything else from the equation. What Yeti said was basically the same thing I said above - I'm just more long-winded. As for working for a while after a resource share change, it will - until all the work for everything "low" that you had on the system is done. Then it'll fall into what you're seeing.
|
|
Destroyer_Kahn Send message Joined: 13 Oct 05 Posts: 9 Credit: 63,540 RAC: 0 |
Why are you mad at Predictor? |
|
Tern Send message Joined: 25 Oct 05 Posts: 576 Credit: 4,702,007 RAC: 0 |
Why are you mad at Predictor? Lack of communication from project staff on anything _important_ - they pop up every once in a while and answer simple questions, but not the big, "show stopper" problems, even if "ATTENTION DEVS" is in the thread title. They have a couple of known bugs in their app, one where it won't _quit_ when told to, and one that locks up your whole system with a dialog box. Rosetta has similar problems, but the Rosetta staff are online talking about what they're doing to fix them. Predictor staff won't even answer emails. And Rosetta's problems are _new_, where Predictor's have been present for months, untouched. SETI is just as bad, I suppose, but they at least have the excuse of near-zero funding, and a huge number of participants. (And a 6 year history of minimal communications.) Predictor seems over the course of the last six months to have gone from "great" to "lousy" at communicating. When I hit 10,000 credits for them, I gave up and detached. I'll check back in a few months.
|
|
Paul D. Buck Send message Joined: 17 Sep 05 Posts: 815 Credit: 1,812,737 RAC: 0 |
Why are you mad at Predictor? Me too ... If you are heavy into Bio stuff, you have choices with Predictor@Home, Rosetta@Home, and WCG (who use an older version of Rosetta the application program this is being worked on in Rosetta@Home). My personal interest is usually biased towards physics (no cutting up dead frogs for me ...), but, for the moment, the communication and interaction here is so high and interesting they have commanded a pretty high commitment from me (25%), higher than would be "normal" based on my interest profile. SETI@Home has plenty of people so I won't be missed, but they get a 5% share anyway. When AstroPulse comes out I wil rethink that ... WCG is getting LHC's share of 10% (down from 25% because of Rosetta@Home) and so basically has replaced Predictor@Home which I have supported for almost the entire time the project has been alive and in production. Again, long winded like Bill ... don't talk to me or answer show-stoppers ... lose my participation. I have said this in other posts, and partly, I think, misunderstood; I feel that the project should have a daily presence in the forums. Not to answer the trivia, Bill does that. What he misses I try to get, what I mess up, Ingleside corrects ... But, the project needs to be here ... and even if it is to only say ... we havent found it yet ... talking to us. Broken record here, but the time to talk to the participants is part of the cost of the "free" resource. Keep me interested, or I will go elsewhere ... a seller's market. As a reasonably long supporter of DC projects (since 19 Jul 2000 at 15:31:49 UTC to be precise) I was "locked in" to single projects. With BOINC, I can drop a project in seconds and add a new one ... But, that is why *I* am mad at Predictor@Home ... :) |
|
O&O Send message Joined: 11 Dec 05 Posts: 25 Credit: 66,900 RAC: 0 |
Why are you mad at Predictor? Me Three ... For all of the above ... For finding out, even though it takes less time to crunch WUs (More results for them), hense, offers my computers back the lowest Credits / 1 sec of CPU time when compared to other projects. Credits/1 sec of CPU time PrimeGrid = 0.0027414 RAH = 0.0027373 uFluids = 0.0022636 SAH = 0.0020286 Predictor = 0.0017698 It is a waste of resources. And ... For reading this in their Q&A in response to the demanding inquiries from the participants to have screen savers: "At the moment there are other issues that we feel are of a greater priority, so the screen saver is on the back burner." They have other issues that they feel of a greater priority...than what the participants are doing for them ...what they simply want back. For all of the above... I feel that my greatest Periority is: To keep on detached. O&O (A tangled heap of unpleasantness...Good grief, What-a-Mess! ) |
|
Tern Send message Joined: 25 Oct 05 Posts: 576 Credit: 4,702,007 RAC: 0 |
For finding out, even though it takes less time to crunch WUs (More results for them), hense, offers my computers back the lowest Credits / 1 sec of CPU time when compared to other projects. The highest is Climateprediction. AndyK's "pending credit" calc will figure credits/hour for you very simply. (But not for CPDN as "pending" is meaningless...) For reading this in their Q&A in response to the demanding inquiries from the participants to have screen savers: The lack of a screensaver doesn't bother me much. What _does_ bother me is that fatal errors in the application that lock up a machine and allow no further processing on ANY project, and requires a mouse click (forget remote...) to fix, aren't any HIGHER on their priority list than the screensaver is! Nor are any of the other bugs and problems people are reporting.
|
|
Fuzzy Hollynoodles Send message Joined: 7 Oct 05 Posts: 234 Credit: 15,020 RAC: 0 |
If you force your computer to run WU's from a project with a low share by suspending the other projects, the problems will be, as I've understood it, that when you resume these projects, the debt will make them "catch up" until the depts are "paid" back. So, when you're attached to so many projects and some with so little share, Seti with the biggest share will catch up again by running until the long term debt is down again. This is the same that happens, if a project goes into panic mode and run, until the WU's have finished, before the manager swaps back to the other projects. After uploading the "panic'ed" WU's you'll also see the other projects run for a while, while the long term debt is brought down. I only run 3 projects at a time myself, with a 50% - 30% - 20% share, and I think that the persons, who run 5 or more projects on one computer, and do it successfully, have a more equal share. (And yes, they rarely run ClimatePrediciton on that computer also!) Am I right in this, Paul and Bill? And for debt, if you don't really understand it, look in Paul's Wiki about it: http://boinc-doc.net/boinc-wiki/index.php?title=Long_Term_Debt And to monitor your debt, you can download it from here: http://home.austin.rr.com/skipsjunk/util/boincdv.html [b]"I'm trying to maintain a shred of dignity in this world." - Me[/b] 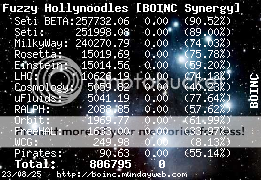
|
|
arcturus Send message Joined: 22 Sep 05 Posts: 16 Credit: 525,440 RAC: 0 |

|
|
Paul D. Buck Send message Joined: 17 Sep 05 Posts: 815 Credit: 1,812,737 RAC: 0 |
I only run 3 projects at a time myself, with a 50% - 30% - 20% share, and I think that the persons, who run 5 or more projects on one computer, and do it successfully, have a more equal share. (And yes, they rarely run ClimatePrediciton on that computer also!) Well, no not in my experience. Though my resource shares have been fluctuating madly these last few weeks, in part coming to gip with Preditor@Home's lack of involvement and depression pulling at me. BUT, my last major configuration was as follows: CPDN 20% SAH 5% EAH 30% PPAN 0% LHC 0% (no work - so no point) RAH 25% SDG 1% PG 1% WCG 18% Now, on my "better" computers this means that with 4 "Logical" CPUs I have 4*24, or 96 hours a day to schedule. Round that up for ease, and call it 100. So, that means that the smallest project still have time to run 1-2 work units a day. And, that is what I see ... CPDN, EAH, RAH, and WCG are almost always in work on AT LEAST one CPU (of 20 total). So, the resource shares work out well for the multi-cpu systems with the more unfortunate problem of "thrashing" as work is completed and the CPU scheduler changes projects. This means on a 4 CPU system you see a change in work about eveery 15 minutes ... :( Does this answer the question? My bottom line is that even with CPDN work on all my systems from the single CPU computers (2 each) to the 4 CPU systems (also 2 each) the allocation of time to each of the 5-7 projects does follow the basic resource share over time, even over the day. Though for the low percentage projects I do not always have work on hand for all comptuers for those projects (particularly for the slower or single CPU systems). That being said, I tend to not fuss with the settings too much, though I do have an occasional habit to "flush" the completed work built up once a day. FOr example, I have 62 completed results queued up right now. This is unusual but is a consequence of my mood shift ... |
Message boards :
Number crunching :
No New Work

©2026 University of Washington
https://www.bakerlab.org