Posts by Mad_Max
|
21)
Message boards :
Number crunching :
L3 Cache is not a problem, CPU Performance Counter proves it
(Message 97689)
Posted 27 Jun 2020 by Mad_Max Post: And Runtime is no good as Runtimes are fixed. Credit is no good as it is based on APR. Sorry for a late reply (forget to subscribe to thread initially). Runtimes are NOT fixed. The target CPU time is fixed in the settings, yes. But actual run times can vary significantly from it. Some task ends prematurely - usually if there is an some errors during processing or WU hits internal "max decoy limit" (there is an instruction in each WU to stop processing data if set number of decoys already generated and sent results to server, ignoring fact it did not reach target CPU time). And on the other case some WUs exceed target CPU time significantly - usually it happens if WU works on really hard/big models and generation of one decoy on such hard targets can take few hour of CPU work. And target CPU time is checked only between decoy, CPU time trigger does not interrupt calculation of already started decoy until it fully finished or watchdog kick-in (usually it set to CPU target time + 4 hours) and abort the task . That is why I count actual CPU time: take some(more is better) completed WUs, sum up all CPU times used by it, sum up all the credit generated. Divide sum of the credit by sum of all CPU time consumed. And you got a fairly accurate estimate of real host performance without waiting a LONG time for the average indicator (RAC) to stabilize. Usually grab(C&P) all recent WUs from result tables into Excel/Calc spreadsheet, And about decoys - based on my observation - yes, there is almost linear relation - e.g. double CPU runtime of WU and it will produce about twice number of decoys. With same type of WU and same hardware of course. Moreover, it the number of decoys generated is the main factor for calculating credits for a successfully completed task at server after reporting. Its like simple formula: Cr granted = decoy count in reported WU x "price" of one decoy. Host CPU benchmarks and APR is used to determine that "decoy price" but server uses average values collected from many (not sure how many? probable all) host contributing to the same target/work type. Its NOT a BOINC WU "wingmans"(such scheme is used in WCG for example). For R@H it all host getting WUs of a same type/batch (usually hundreds or even few thousands hosts on large batches). So all "anomalies" in benchmarks and AFR smoothed out due to large scale averaging. But for particular host only number of successfully generated decoys determine how much CR it receives for completed WUs. |
|
22)
Message boards :
Number crunching :
no new tasks?
(Message 97667)
Posted 27 Jun 2020 by Mad_Max Post: As of this morning (US Central time), looks like the well has run dry again. There is an option in the BOINC computing preferences "Switch between tasks every xxx minutes" If you increase this value BOINC will switch between project less often. And if you increase it above average WU run time BOINC should switch between projects only after fully competing previous WU. I have it set to 300 min (from default 60 min) and usually BOINC finish already started WUs from WCG before switching back to R@H. And work share set to 100 for WCG (its a default value) and 200 for R@H. |
|
23)
Message boards :
Number crunching :
COVID 19 WU Errors
(Message 97665)
Posted 27 Jun 2020 by Mad_Max Post: There is a good update. Looks like in latest BOINC versions (v 7.16.x and later) BOINC developers finally fixed "waiting for memory" behavior. It no longer conflicts with "leave non-GPU WU in memory while suspended" option. Before fix: If BOINC suspend task due to exceeding allowed RAM usage and option "leave non-GPU WU in memory while suspended" was enabled tasks stays in RAM while "waiting for memory" . And so this way any attempts of BOINC client to free some RAM via suspending some of running WU led to the exact opposite effect: RAM usage only increased(because it consumed by more and more tasks in "waiting for memory" state) until some of tasks or systems as a whole crash due to out of RAM errors. After the fix: BOINC client now ignores "leave non-GPU WU in memory while suspended" options for task in "waiting for memory" state and unload them from RAM anyway regardless of this option. Option now apply to task suspended due to other reasons (like manual user request or CPU switch to another project). So I retract my recommendation made in this post to avoid use of this option on machines with limited memory - provided BOINC client updated to one of the last versions (>= 7.16.x) . Also there is no longer useful to limit number of R@H task running in parallel via <max_concurrent> </max_concurrent> settings in the app_config.xml Its more efficient and easy to tune "use at most" memory settings. And BOINC should do the rest automatically to not exceed these values. This should be this way from beginning, but unfortunately due to some errors in the BOINC code did not work as expected. But it work now! |
|
24)
Message boards :
Number crunching :
Task start optimisation suggestion
(Message 97663)
Posted 27 Jun 2020 by Mad_Max Post: And finally this optimization was implemented! In Rosetta v. 4.20 and later: https://boinc.bakerlab.org/rosetta/forum_thread.php?id=12554&postid=95678#95678 And it works fine and cut down disk space usage and disk I/O load by at least an order of magnitude! (> 10 times) |
|
25)
Message boards :
Number crunching :
Peer certificate cannot be authenticated with given CA certificates
(Message 96951)
Posted 31 May 2020 by Mad_Max Post: Yes, no need to restart anything. After replacing (or editing) cert file just press retry (on "Transfers" tab) and Update (on "Projects" tab) is enough to fully resume normal work. Although full BOINC restart will work too of course. |
|
26)
Message boards :
Number crunching :
Peer certificate cannot be authenticated with given CA certificates
(Message 96941)
Posted 31 May 2020 by Mad_Max Post: Editing ca-bundle.crt fixed upload/download error. Thanks for the hint! Although I do not understand why such a problem arose at all! Only last week I installed the most recent version of BOINC - and it experienced the same problem. I also had to edit the certificate file. Such things should be fixed by BOINC programmers centrally, rather than manually editing certificate file by each user. |
|
27)
Message boards :
Number crunching :
Rosetta 4.1+ and 4.2+
(Message 96932)
Posted 30 May 2020 by Mad_Max Post: I updated the rosetta app version to 4.20 for the arm, android, and mac platforms. I will update the remaining platforms in the next day or so. Finally! Crunchers suggested and waited for this upgrade for so many years! And it finally here and works fine. Thanks! |
|
28)
Message boards :
Number crunching :
Rosetta 4.1+ and 4.2+
(Message 96930)
Posted 30 May 2020 by Mad_Max Post: Regarding WinXP and memory: For Win XP reason why all Rosetta WU is fails at the start - it can not extract files stored in zip files. It produce errors like this unzip: cannot find either ../../projects/boinc.bakerlab.org_rosetta/rep445_0040_symC_reordered_0001_propagated_0001_A_v7_data.zip or ../../projects/boinc.bakerlab.org_rosetta/rep445_0040_symC_reordered_0001_propagated_0001_A_v7_data.zip.zip. While all files mentioned in errors actually present and undamaged - can open and extract them manually, archive integrity checks pass OK . Probable R@H (or never version of BOINC ?) try to use unzip buit-in in Windows 7 and later only. Example all tasks from this machine: https://boinc.bakerlab.org/rosetta/results.php?hostid=1252064 If admins not gonna fix it and drop WinXP support instead (which is quite understandable - i will run WCG an all WinXp machines then - it works just fine on WinXP ) then disable work distributions for this OS and give a proper error when such clients contact server for job.. Currently it is just waste of resources - server sent tasks they downloaded, all failed, reported to server, get more tasks, fails, etc. Only limited by hitting WU daily quota. P.S. Still use WinXP on one of computers for all last years which running 100% online (always connected) and for active web browsing too (FireFox 52.9). No single virus or security breach/issue for lat 6 (six) or 7 years! While have had some security issues on never Win7 and Win 8.1 machines during this period and in the same home network!. I guess it just not worth for hackers and virus makers to "support" XP too lol . All security breaches stopped about same time WinXp official support is dropped by Microsoft. Plan to use it for at least 1 or even 2 years more. |
|
29)
Message boards :
Number crunching :
Task start optimisation suggestion
(Message 94417)
Posted 14 Apr 2020 by Mad_Max Post: Yes, it is a very good idea. And BOINC have right tools to do so. And it very useful not only for SD cards devices but for regular computer with BOINC installed on HDD too. Starting a lot of R@H WUs (on many cores/threads CPUs) from HDD is a very slow process due to multiple databases unpacking and often cause errors and WU failures. Also it can save a lot of disk space on SSDs: each running R@H WUs consume about 1 GB of disk space 95-99% of which used by copies of a same database (~960 MB, 5300 files in latest revision) common for all WUs. But it was proposed many times for few years already (I also wrote about this several times) and nothing done on the issue. |
|
30)
Message boards :
Number crunching :
L3 Cache is not a problem, CPU Performance Counter proves it
(Message 94416)
Posted 14 Apr 2020 by Mad_Max Post: Average processing rate calculated by BOINC is not relevant for R@H. These numbers are useless because R@H WUs have no fixed length but have fixed FLOPS count set on the BOINC server = 80 000 GFLOPs. It useful only for fixed work WUs used in most of the other projects. But not in R@H ANY CPU running R@H with default 8 hours target runtime will give about 2.5-3 GFLOPS as average processing rate: 80000/(8*60*60). Regardless of real CPU speed. Pentium 4 and Core i9 have similar values because FLOPS count is fixed and runtime is fixed too. If you change target CPU time - you will get significant change in "average processing rate" reported by BOINC. Any other differences are random variations, it says nothing about actual CPUs speeds. Comparing real computation speed for R@H is a hard task. You need to count run-times and numbers of decoys or credits generated during that run-times while selecting WUs of a same type. Or averaging over large numbers of different WUs to smooth out the differences between them. |
|
31)
Message boards :
Number crunching :
L3 Cache is not a problem, CPU Performance Counter proves it
(Message 94415)
Posted 14 Apr 2020 by Mad_Max Post: 2 bitsonic Nice data digging and testing. I did similar testing about a year ago, and also have not found any significant performance impacts from running multiple R@H WUs. Not not specifically on the use of L3 cache, but the general effect of the number of simultaneously running R@H tasks on the speed of calculations. There is an impact of course, but it very minor. I used average credits (which accounted in proportion to successfully calculated decoys) per day per CPU core as benchmark averaging over at least 20-30 WUs each measurement to mitigate different work types profiles in different WUs. And running 6 WUs in parallel on 6 cores CPU or 8 WUs on 8 core CPU or even 16 WUs on 8 core CPU gives only about 10-25% performance hit: eg 6 WUs running on 6 cores CPU with 6 MB L3 yields about 5 times more useful work compared to 1 WU running on same 6 cores CPU + 6 MB L3. This all L3 fuss with statement like "running only 1 WU is faster compared to running WUs on all cores" sounds like a pure nonsense for me. All data i have seen on my computers and from a few team-mates prove the opposite: there is a some performance hits from high WUs concurrency, but they are minor and running more threads always increase total CPU throughput if not constrained by RAM volume (no active swapping) . Even running WUs on virtual cores (HT / SMT threads) gives some total speed boost: it decrease 1 thread speed significantly but still increasing total CPU throughput from all running threads combined. For example: running 16 R@H WUs on my Ryzen 2700(8 cores + SMT, 16 MB L3) is ~17 percent faster (more total throughput/more decoys generated) compared to running 8 R@H WUs on same system. Yes, there is some problems on heavy working machines running 16-32 or more R@H WUs in parallel. But such problems are came from a very high RAM usage(volumes) and sometimes a very high disk (I/O) loads during multiple WUs startup in such systems. And not related to any issues with CPU caches. |
|
32)
Message boards :
Number crunching :
COVID 19 WU Errors
(Message 93882)
Posted 8 Apr 2020 by Mad_Max Post: Thanks for posting your experience. At the same time, many have found problems running <without> that option checked at times when memory is less of an issue. It's hard to know what to do for the best. I would certainly say, when memory isn't the issue, that option should always be checked for the same reason you mention - Boinc doesn't seem to handle memory well after coming out of sleep or after a shutdown. Yes, I agree with you. If RAM usage is not issue then better to keep this option on. As it help to avoid few other known BOINC issues (for example with sleep mode and with lost of some progress of running WUs during projects switches by BOINC scheduler on multiprojects setups especially if checkpoints are not working properly ). |
|
33)
Message boards :
Number crunching :
GPU WU's
(Message 93157)
Posted 3 Apr 2020 by Mad_Max Post: As a result modern GPU only just few times faster compared to modern CPUs. And only on task well suitable for highly parallel SIMD computation. On tasks non well suitable for such way of computation it can be even slower compared to CPUs.Actually, the facts say otherwise. It just rubbish rather than facts. Either you misunderstood / counted something wrong. For example, you probably took the runtime of WU on 1 thread / core of the CPU (and not the whole processor), and compare it with the runtime of a job using an entire GPU (plus some from CPU as all GPU apps do) . Or the programmers of SETI are completely unable to use modern CPUs normally. Only 40% boost form AVX compared with plain app without any SIMD is pity and puny: on a code/tasks suitable for vectorization it should gain 3x / +200% speed or more, and if code/task is NOT suitable for vectorization gain can be low but such tasks can not work effectively on GPU at all. Because both GPU programming and CPU SIMD programming needs the same (because all current GPUs cores are wide SIMD engines inside), but SIMD for CPU is simpler to implement. current high end CPUs: Intel Core i9-9900k is capable of ~450 GFLOPS with dual precision or 900 GPLOPS at single precision calculations AMD Ryzen 9 3950X: ~900 GFLOPS DP and 1800 SP. AMD Threadripper 3990X: 2900 GFLOPS DP and 5800 SP. Peak speeds of few current high end GPUs AMD VEGA 64 = 638 GFLOPS DP and 10215 SP AMD RX 5700 XT = 513 GFLOPS DP and 8218 SP NVidia RTX 2080 = 278 GFLOPS DP and 8 920 SP NVidia RTX 2080 Ti = 367 GFLOPS DP and 11750 SP And it’s much easier to get real app speed closer to the theoretical maximum on the CPU than on the GPU. And all GPU computation also need additional support/use of resources from CPU to run. Both facts reducing speed gap even further as we move from theoretical potential (shown above) to practical computing. As i said: modern GPU only few times faster compared to modern CPUs, not ~100x (if you properly use all cores and SIMD extensions). And only if used for single precision calculations. On dual precisions GPUs usually even slower compared to CPUs at least for all "consumer grade" GPUs (there are special versions of GPUs for data centers and supercomputers with high DP speeds like NV Tesla or AMD Instinct, but they priced few times more compared to consumer/gamer counterparts GPUs and usually not sold to retail customer at all) . |
|
34)
Message boards :
Number crunching :
Rosetta x86 on AMD CPU
(Message 93156)
Posted 3 Apr 2020 by Mad_Max Post: Does Rosetta obey using a max_concurrent statement in an app_config? I am having issue with out of memory issues preventing my gpu tasks from running and I am not able to well control just using the %cpu setting in Preferences. Yes, it works fine. I am using it for ~1.5 month already after huge COVID WUs stated to pop-up hoarding RAM. But there is a little trick because R@H have 2 different application lines (rosetta and rosetta mini) and you need to set rules for both apps or use <project_max_concurrent> option instead of just max_concurrent to set restriction on the whole project level. Reference for all who does not know how to use app_config for such things: https://boinc.bakerlab.org/rosetta/forum_thread.php?id=13644&postid=93152#93152 |
|
35)
Message boards :
Number crunching :
0 new tasks, Rosetta?
(Message 93155)
Posted 3 Apr 2020 by Mad_Max Post:
It actually simple and can easily correlated. A very simple formula: 7 WCG points = 1 BOINC point ( 1 cobblestone) or vice versa. It just legacy from very old times when WCG was stand alone project using own software platform including own point calculation rules and formulas . Which migrated to BOINC platform later but point basis remains the same for compatibility issues with data and stats generated in pre-BOINC era . |
|
36)
Message boards :
Number crunching :
COVID 19 WU Errors
(Message 93152)
Posted 3 Apr 2020 by Mad_Max Post: To all who have problems with too high memory consumption. To allow "waiting for memory" functions works properly please disable (if enabled) "leave non-GPU WU in memory while suspended" . On web preferences or local client: 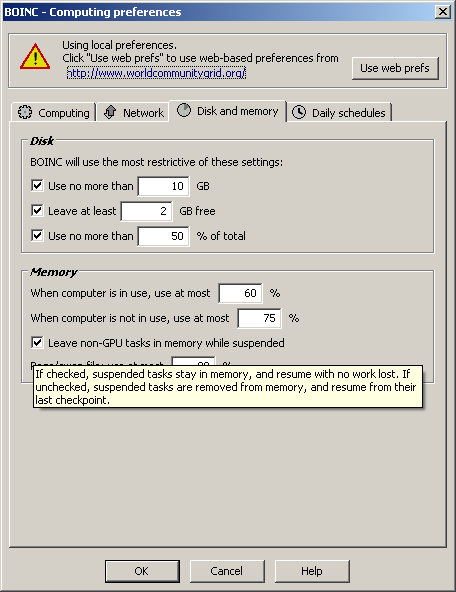 BOINC flaws does not allow it to manage memory properly with this option active - due some errors it does not count memory consumption by such suspended tasks and can hoard all system RAM which lead to crashes/reboots/or very intensive disk swapping. Because if BOINC see what RAM consumption is too high (above limit set in the preferences) it try to suspend some of WUs to reduce RAM usage ("waiting for memory"), and try to start other WUs (as it can use less RAM compared to suspended and CPU cores will not go idle). But if "leave non-GPU WU in memory while suspended" option is active such measures do not decrease RAM usage, but only increase it even more worsen situation. Or as alternative use direct manual restriction to BOINC which limit how many R@H tasks can be run simultaneously and fill the remain CPU cores with tasks from other BOINC projects with low RAM usage. My advice would be join WCG if you look for other good disease fighting/medicine projects. It usually use small amounts of RAM (< 100 MB per WU) and almost do not compete for RAM with R@H WUs. To do so you can create file with name "app_config.xml" And place it in the R@H home folder in BOINC data folder ( /projects/boinc.bakerlab.org_rosetta/app_config.xml) There is a template for such file <app_config>
<app>
<name>minirosetta</name>
<max_concurrent>6</max_concurrent>
</app>
<app>
<name>rosetta</name>
<max_concurrent>3</max_concurrent>
</app>
</app_config>
In this example BOINC is allowed to run up to 6 "minirosetta" WUs at max (which usually use relative modest amounts of RAM like 150-400 MB) and up to 3 full rosetta WUs including new which can use huge amounts of RAM (up to 3000 MB per biggest WUs). And up to 9 WUs per R@H project total (6+3). You can play with number for your system. My advice will be 2 GB per rosetta WU and 1 GB per minirosetta WU. For example if your system has 16 GB RAM with 8core/16 threads CPU: limit it to something like 6 Rosetta + 4 minirosetta WUs to avoid out of RAM issues. Or 4 + 8. And let WCG (or other project of your choice) to use all remaining CPU slots. Also of you low on RAM but want ROSETTA ONLY setup - consider turning off HT/SMT features on you CPU. It decrease total CPU throughput (by 20-30% on average) but also decrease RAM usage by two fold because number of concurrent running WUs will be halved but speed of running each WU will increase substantially. P.S. 2 Mod.Sense Please copy or link this message as guidance to other new users having issues with too high RAM usage in other threads. I think this issues and questions will be quite common in the coming days/weeks with that flow on new users boarding in. |
|
37)
Message boards :
Number crunching :
Default workunit preferred runtime increases to 16 hours.
(Message 93149)
Posted 3 Apr 2020 by Mad_Max Post:
It is a very good idea. And it actually relatively easy to implement because almost all R@H WU generate a lot (from few to few hundreds) models or "decoys" per each WU. And such "decoys" not intermediate results , it complete final results(from client side point of view) which can be used independently from the rest results from same WU (even if WU fails later - already generate decoys are useful). Or all of them (even after WU is fully completed) can be regarded as intermediate results. Because scientists, for each studied target, need to get from several thousand to hundreds of thousands of such "decoys", but it does not matter how they were broken into WUs or in what order and how they arrived to the server. Just the more you get collected, the better and more reliable the final result will be, which is any case obtained only after post-processing on the server, and not on the client computers of the volunteers. |
|
38)
Message boards :
Number crunching :
Stalled downloads
(Message 93148)
Posted 3 Apr 2020 by Mad_Max Post: So maybe allow repeated attempts to download for a maximum 24hrs, else abort? But could be a loss of connectivity at the user end, or at the project end? Connectivity detection is also partially broken in BOINC clients: If BOINC client can not download file or contact project server it contacts "reference site" which is google.com for last few years. If it get "HTTP 200 - OK" response from google - all work as expected: BOINC understands there are problem with particular project but Internet connection is OK and proceeds with other projects. But if google return any other response(not "200 OK") - BOINC stupidly interprets it as connectivity issues (no internet connection) and temporarily ceases all internet activity and increase "back-off" timer each time. And Google often returns other codes - because a lot of such similar automated requests from thousands of computers around the world running BOINC often trigger the anti-bot filters of Google (it blocks such requests and offers to solve CAPTCHA to continue work). BOINC of course can not understand it and react to this by declaring "connectivity issues". Although the fact that it was able to get an error message from Google (no matter which and for what reason) means the exactly opposite - that the Internet connection is working OK. |
|
39)
Message boards :
Number crunching :
Stalled downloads
(Message 92373)
Posted 27 Mar 2020 by Mad_Max Post:
I highly doubt that this could be a disk problem. Now almost all disks and file systems use a sector / cluster / block / page size of 4 KB or (rarely) more. Work with the disk is done in portions of 4 kb, which are either fully readable or not readable at all. I can’t imagine the situation when the disk successfully read part of one sector and stopped in the 2nd half of same sector. But some damage/corruption to the file system (the logical level of files organization, not physical disks) is possible. In many file systems, the smallest files (up to several KB in size) are stored not in separate blocks on the disk, but directly in the service tables of the file system. And if these tables are damaged in any way, this could somehow explain the repeated (reproducible) problems with the same file at same point and why such problems only occur with very small files, but have never met with large files. Because storage of larger files are organized differently in the filesystem: for larger files filesystem stores only "meta" information in service tables(like file name/size/date&time created/etc) and file itself is stored as a separate block on the disk. For small files file itself(content) is stored in same same place with "meta" information. |
|
40)
Message boards :
Number crunching :
Stalled downloads
(Message 92144)
Posted 22 Mar 2020 by Mad_Max Post: Never seen any big files stuck. Only small, usually in 1-4 KB range. And only from Rosetta, all other attached projects running OK. P.S. Still happening - got more stuck downloads 2 days ago. Files were: 9v1nm_gb_c2489_9mer_gb_002321.zip (3.5 KB) twc_method_msd_cpp_10v4nme4_466_result_1037_msd.zip (3.2 KB) |
Previous 20 · Next 20

©2025 University of Washington
https://www.bakerlab.org