minirosetta_database directory in slot
Message boards : Number crunching : minirosetta_database directory in slot
| Author | Message |
|---|---|
|
Raistmer Send message Joined: 7 Apr 20 Posts: 49 Credit: 798,155 RAC: 0 |
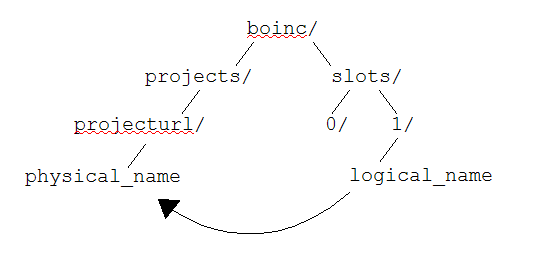
It's 960MB per slot (task). Looks like it's extracted database_357d5d93529_n_methyl.zip from project directory. Is it indeed just extracted zip? Or some modifications to files inside minirosetta_database slot's directory are done through the task processing? |
|
Mod.Sense Volunteer moderator Send message Joined: 22 Aug 06 Posts: 4018 Credit: 0 RAC: 0 |
I believe it is just used as a reference file for some of the current work units. Why are you asking about it? Rosetta Moderator: Mod.Sense |
|
Raistmer Send message Joined: 7 Apr 20 Posts: 49 Credit: 798,155 RAC: 0 |
I believe it is just used as a reference file for some of the current work units. Why are you asking about it? I'm asking cause if data only being read from that directory after extraction - it's _very_ inefficient way to do work. Much (per 960MB per each task processed by the host) better way would be to extract it once into project directory and read from where when needed. It would save both HDD space (no need additional 960MB per slot, especially important on manycore systems) and reduce startup time for task (time to extract 960MB of data). And obviously will lower HDD wearout. |
|
Raistmer Send message Joined: 7 Apr 20 Posts: 49 Credit: 798,155 RAC: 0 |
Well, I calculated MD5-sums for 4 minirosetta_database directories in 4 slots for tasks on different stage of completion on one of my hosts. And they all are IDENTICAL as expected. So, this directory doesn't get modified through task run, it's read-only data. But why for the god's sake to extract it into SLOT directory for each task again?? What a waste of participant's resources?? |
|
Jonathan Send message Joined: 4 Oct 17 Posts: 43 Credit: 1,337,472 RAC: 0 |
Isn't this issue a BOINC problem rather than Rosetta problem? That is just the structure BOINC does. |
|
Admin Project administrator Send message Joined: 1 Jul 05 Posts: 5146 Credit: 0 RAC: 0 |
Indeed this is not efficient but there currently is no easy workaround that we know of since Rosetta is dependent on the database directory structure. If anyone knows of an easy workaround, I'm all ears. The Rosetta application depends on the database directory structure. This database holds all the required score, chemical, sampling, rotamer, etc. parameters and libraries that are the backbone of all the computations and a result of many years of research and development. These parameters may or may not change with application updates. For example, for the COVID-19 specific jobs, we had to significantly increase the size of the database to include an improved local protein structure fragment library in addition to side chain motif libraries to enable the interface design protocol. These are parameters/libraries that have been developed and continue to be developed in the lab through careful analysis and research of native protein structures and molecular structures in general. |
|
Keith T. Send message Joined: 1 Mar 07 Posts: 58 Credit: 34,135 RAC: 0 |
Indeed this is not efficient but there currently is no easy workaround that we know of since Rosetta is dependent on the database directory structure. If anyone knows of an easy workaround, I'm all ears. The Rosetta application depends on the database directory structure. This database holds all the required score, chemical, sampling, rotamer, etc. parameters and libraries that are the backbone of all the computations and a result of many years of research and development. These parameters may or may not change with application updates. For example, for the COVID-19 specific jobs, we had to significantly increase the size of the database to include an improved local protein structure fragment library in addition to side chain motif libraries to enable the interface design protocol. These are parameters/libraries that have been developed and continue to be developed in the lab through careful analysis and research of native protein structures and molecular structures in general. How about this https://boinc.berkeley.edu/trac/wiki/BoincFiles ? You might also like to have a look at the suggestion that I made on RALPH nearly 12 years ago https://ralph.bakerlab.org/forum_thread.php?id=395#4109 |
|
Admin Project administrator Send message Joined: 1 Jul 05 Posts: 5146 Credit: 0 RAC: 0 |
The directory structure has to be maintained and I am not aware of any way to create a directory in the project directory and keep it sticky. Can we extract into the project directory without the client cleaning it up? Any solution will require an application update, and to my knowledge a solution can be developed but would most likely require a BOINC client update. |
|
Keith T. Send message Joined: 1 Mar 07 Posts: 58 Credit: 34,135 RAC: 0 |
The directory structure has to be maintained and I am not aware of any way to create a directory in the project directory and keep it sticky. Can we extract into the project directory without the client cleaning it up? Any solution will require an application update, and to my knowledge a solution can be developed but would most likely require a BOINC client update.
https://boinc.berkeley.edu/trac/wiki/BoincFiles |
|
Keith T. Send message Joined: 1 Mar 07 Posts: 58 Credit: 34,135 RAC: 0 |
Some other projects e.g. SETI, have been using this feature of BOINC for at least 15 years, so I don't think a new client would be required. |
|
Raistmer Send message Joined: 7 Apr 20 Posts: 49 Credit: 798,155 RAC: 0 |
Isn't this issue a BOINC problem rather than Rosetta problem? That is just the structure BOINC does. No. It's issue of improper project configuration. |
|
Raistmer Send message Joined: 7 Apr 20 Posts: 49 Credit: 798,155 RAC: 0 |
Indeed this is not efficient but there currently is no easy workaround that we know of since Rosetta is dependent on the database directory structure. If anyone knows of an easy workaround, I'm all ears. The Rosetta application depends on the database directory structure. This database holds all the required score, chemical, sampling, rotamer, etc. parameters and libraries that are the backbone of all the computations and a result of many years of research and development. These parameters may or may not change with application updates. For example, for the COVID-19 specific jobs, we had to significantly increase the size of the database to include an improved local protein structure fragment library in addition to side chain motif libraries to enable the interface design protocol. These are parameters/libraries that have been developed and continue to be developed in the lab through careful analysis and research of native protein structures and molecular structures in general. Solution is quite simple. Put it into project dir, not slot dir. Then either reference it directly as I did on SETI, or use BOINC soft link mechanism you already used for results and executables themselves. |
|
Raistmer Send message Joined: 7 Apr 20 Posts: 49 Credit: 798,155 RAC: 0 |
The directory structure has to be maintained and I am not aware of any way to create a directory in the project directory and keep it sticky. Can we extract into the project directory without the client cleaning it up? Any solution will require an application update, and to my knowledge a solution can be developed but would most likely require a BOINC client update. Well, client doesn't clean up ANYTHING it doesn't know. And it knows ONLY that referenced in XML files. So, if your app just extract very same dir into project folder and put same "extraction done" file also into project folder and then will read that flag on start - all will work the same besides participants drives will not be trained by GB per task. |
|
Admin Project administrator Send message Joined: 1 Jul 05 Posts: 5146 Credit: 0 RAC: 0 |
So a couple questions seem to have been answered, that you can extract into the project directory and these files will not be cleaned up by the client. Great, thanks! If this is indeed the case then we can develop a mechanism that extracts into the project directory but we will also need to develop a versioning and proper cleanup method so things will not be affected upon application updates (or space taken up with old database files) since the database may not be forward and backward compatible which will present an issue if there are two app versions running at the same time. |
|
funkydude Send message Joined: 15 Jun 08 Posts: 28 Credit: 397,934 RAC: 0 |
Indeed this is not efficient but there currently is no easy workaround that we know of since Rosetta is dependent on the database directory structure. If anyone knows of an easy workaround, I'm all ears. The Rosetta application depends on the database directory structure. This database holds all the required score, chemical, sampling, rotamer, etc. parameters and libraries that are the backbone of all the computations and a result of many years of research and development. These parameters may or may not change with application updates. For example, for the COVID-19 specific jobs, we had to significantly increase the size of the database to include an improved local protein structure fragment library in addition to side chain motif libraries to enable the interface design protocol. These are parameters/libraries that have been developed and continue to be developed in the lab through careful analysis and research of native protein structures and molecular structures in general. Look at WCG (World Community Grid). They do not copy all the data into every single slot. They don't even copy the executables. It seems they use 1KB files which I assume act as pointers/symlinks, but don't quote me on that. Looking at the logs of WCG completed tasks, I see a reference to the /projects/ directory directly. FYI this is the reason I gave up on this project and moved to WCG (waiting on their COVID project) The currently implementation was obviously designed back in the 4 core days. Not acceptable to use ~24GB of storage for 24 tasks (threads) today. I'll come back if it's ever fixed. |
|
Raistmer Send message Joined: 7 Apr 20 Posts: 49 Credit: 798,155 RAC: 0 |
So a couple questions seem to have been answered, that you can extract into the project directory and these files will not be cleaned up by the client. Great, thanks! If this is indeed the case then we can develop a mechanism that extracts into the project directory but we will also need to develop a versioning and proper cleanup method so things will not be affected upon application updates (or space taken up with old database files) since the database may not be forward and backward compatible which will present an issue if there are two app versions running at the same time. yep, versioning is required. The simplest way is to add versioning info to the name of "root" directory of DB. I did same with files, not dirs, but cause from OS point of view file and directory are essentially the same dir should survive just as good as file. And actually we had additional directories in project folder too (created by anonymous app installer). So, yes, dirs definitely should survive. But also yes, this mean your app should be responsible of keeping track on them and delete when unneeded. It's quite "direct" way, More sophisticated way is to fully use BOINCs "soft" links mechanism. It works perfectly with huge database on Einstein at home (data files added to project dir when new tasks needed them and deleted when batch of corrresponding tasks are gone), but they use "plain" DB of files, w/o additional directory structure. Will soft links work with directories or not - better consult with BOINC support staff or experiment. |
|
Admin Project administrator Send message Joined: 1 Jul 05 Posts: 5146 Credit: 0 RAC: 0 |
Completely agree. If there's a way, we can do it. I can look into this and test on our ralph project. But this will take some time since it will require an application update. |
|
Raistmer Send message Joined: 7 Apr 20 Posts: 49 Credit: 798,155 RAC: 0 |
So a couple questions seem to have been answered, that you can extract into the project directory and these files will not be cleaned up by the client. Great, thanks! If this is indeed the case then we can develop a mechanism that extracts into the project directory but we will also need to develop a versioning and proper cleanup method so things will not be affected upon application updates (or space taken up with old database files) since the database may not be forward and backward compatible which will present an issue if there are two app versions running at the same time. yep, versioning is required. The simplest way is to add versioning info to the name of "root" directory of DB. I did same with files, not dirs, but cause from OS point of view file and directory are essentially the same dir should survive just as good as file. And actually we had additional directories in project folder too (created by anonymous app installer). So, yes, dirs definitely should survive. But also yes, this mean your app should be responsible of keeping track on them and delete when unneeded. It's quite "direct" way, More sophisticated way is to fully use BOINCs "soft" links mechanism. It works perfectly with huge database on Einstein at home (data files added to project dir when new tasks needed them and deleted when batch of corrresponding tasks are gone), but they use "plain" DB of files, w/o additional directory structure. Will soft links work with directories or not - better consult with BOINC support staff or experiment. EDIT: actually to keep track of dirs provided you already do the same for zip-files in project directory is quite simple. Check dirs list in project directory, compare their names with existing zip files and delete all that doesn't match. Again, quite direct, simple and effective. EDIT2: Tomorrow (quite late here) I'll post example how to locate project directory from app "running in slot". |
|
Admin Project administrator Send message Joined: 1 Jul 05 Posts: 5146 Credit: 0 RAC: 0 |
Thanks for your input and suggestions Raistmer. Only way to see is to code it up and test. Will do. Previously I was assuming files get cleaned by this logic as explained on the BOINC wiki: On the client, input files are deleted when no workunit refers to them, and output files are deleted when no result refers to them. Application-version files are deleted when they are referenced only from superseded application versions. But this seems not the case and of course I can look at the client code and/or test this :) Thanks again! |
|
Mod.Sense Volunteer moderator Send message Joined: 22 Aug 06 Posts: 4018 Credit: 0 RAC: 0 |
I believe the versioning control would be the tricky part. One approach would be to wait for all WUs using a given older reference DB to purge from the servers, then use the facility to direct specific commands to hosts when they next hit the scheduler to remove the unzipped structure. But, I believe that approach slows the scheduler, checking one more thing with each scheduler request. (sorry, I'm not finding a link that describes this mechanism to send commands to hosts). I seem to recall that another approach is to have the hosts report in the list of files they have on-board, and use this info. to identify which are obsolete. Rosetta Moderator: Mod.Sense |
Message boards :
Number crunching :
minirosetta_database directory in slot

©2026 University of Washington
https://www.bakerlab.org