Old/New Credit system comparisons
Message boards : Number crunching : Old/New Credit system comparisons
Previous · 1 · 2
| Author | Message |
|---|---|
|
TestPilot Send message Joined: 13 Jun 06 Posts: 29 Credit: 0 RAC: 0 |
I am a Mac guy and if the Macs can not contribute then you don't get my PC either. I do think they use same source code for all platforms. And most likely nothing can be done with old G3/G4/G5 mashines. |
|
STE\/E Send message Joined: 17 Sep 05 Posts: 125 Credit: 4,103,208 RAC: 0 |
Running an Optimized Client at some Projects does have it's benefits in that it makes the CPU work more efficiently thus lowering the time it takes to run that Projects WU's for the same amount of Credit you would get not running an Optimized Client & taking longer to run the WU's. As far as I know running an Optimized Client @ the Rosetta Project does absolutely nothing but Raise Your Benchmark Score to increase the Amount of Credit that you are asking for. It's a moot point now anyway with the new Credit System, you can ask for all you want but your only going to get so much. |
 Trog Dog Trog DogSend message Joined: 25 Nov 05 Posts: 129 Credit: 57,345 RAC: 0 |
It's only crunching Rosetta now. HT is on, it's a prescot and the target runtime is not set(default). It'll crunch 100% rosetta for the next 48 hours then I'll turn HT off.  
|
zombie67 [MM] Send message Joined: 11 Feb 06 Posts: 316 Credit: 6,650,787 RAC: 1 |
You are welcome to look at my computers before they don't have anything to show anymore. FYI, only the account owner can see the machine names. When we look at your machines, we can see only the OS and the HW type. Reno, NV Team: SETI.USA |
|
Dave Wilson Send message Joined: 8 Jan 06 Posts: 35 Credit: 379,049 RAC: 0 |
You are welcome to look at my computers before they don't have anything to show anymore. That is why I added them here. You can see the ID numbers. |
|
Feet1st Send message Joined: 30 Dec 05 Posts: 1755 Credit: 4,690,520 RAC: 0 |
I don't want to reopen an old can of worms, but could someone point me to some technical documentation on what exactly the optimized client is? From reading other posts, it sounds like the stock BOINC benchmarks were unfair over on SETI, in that the BOINC benchmark wasn't indicative of the SETI workload being run on a PC with an optimized SETI application, and so there was a disparity. And so it would make sense that the optimized client (which we all now understand does NOT run any of the Rosetta programs which are 99% of your crunch time) would have a benchmark modified to reflect your ability to crunch... SETI... with an optimized SETI client and a benchmark that reflects your machine's ability to run the code optimizations. Since Rosetta's calculations differ, there's going to be a disparity with ANY benchmark... unless it's one that actually involves crunching Rosetta's programs and WUs. And that's just what we've got now with the new credit system. The only flaw left is that the BOINC benchmarks are still used as a frame of reference back to TFLOPs and overall project credits. And this is proving to be a minor point. Probably because Rosetta is so floating point intensive. Add this signature to your EMail: Running Microsoft's "System Idle Process" will never help cure cancer, AIDS nor Alzheimer's. But running Rosetta@home just might! https://boinc.bakerlab.org/rosetta/ |
|
FluffyChicken Send message Joined: 1 Nov 05 Posts: 1260 Credit: 369,635 RAC: 0 |
I don't want to reopen an old can of worms, but could someone point me to some technical documentation on what exactly the optimized client is? From reading other posts, it sounds like the stock BOINC benchmarks were unfair over on SETI, in that the BOINC benchmark wasn't indicative of the SETI workload being run on a PC with an optimized SETI application, and so there was a disparity. And so it would make sense that the optimized client (which we all now understand does NOT run any of the Rosetta programs which are 99% of your crunch time) would have a benchmark modified to reflect your ability to crunch... SETI... with an optimized SETI client and a benchmark that reflects your machine's ability to run the code optimizations. There's no real documatation. Crunch3rs 5.5.0 added Intel's 'math stuff' to the core client then compiled it against a specific instruction set as requested by people using Intels compiler. (these where similar modification that where don''t to the seti client) Truxoft added extra features to the client (some of which are very useful, shame nobody I know of keeps that going) then compiled it with either Intels or Microsofts compiler, whichever gave better benchemarks at the time. If you want to read about actual modifications to teh Seti@Home source you'll want to visit this site. http://lunatics.at/ (There is a sourceforge parge but I think that quite old) Team mauisun.org |
|
BennyRop Send message Joined: 17 Dec 05 Posts: 555 Credit: 140,800 RAC: 0 |
comp id# seconds oldscore newScr newscr/oldscr credit/second 131105 324,561.25 630.24 159.14 0.252506981 0.000490323 198349 421,410.98 1374.05 379.05 0.275863324 0.000899478 199340 678,100.86 2211.01 585.27 0.264707486 0.000863103 195348 261,159.46 525.43 81.09 0.154330739 0.0003105 191526 161,612.14 526.05 137.11 0.260640624 0.000848389 ppc version 195357 169,638.50 249.46 40.50 0.162350677 0.000238743 203677 163,357.96 250.69 38.93 0.155291396 0.000238311 martin 116,283.70 2039.44 308.35 0.151193465 0.002651704 David Kim 963,013.28 3291.31 1795.58 0.545551771 0.001864543 The PPC version produces more results and comes closer to matching the optimized benchmarks; (0.26 vs 0.15). Martin's benchmarks don't make sense since it's supposed to be a standard client. What's the difference between a 2 cpu PowerMac7,3 and a 4 cpu PowerMac11,2 that would explain the difference in benchmarks? My Athlon 64 2Ghz 3000+ under winXP is getting multiplied by ~1.15; The P4s I ran through are getting between 1.6 and 1.86 of the standard benchmarks by using the new credit system. A P4 with HT on got a credit boost of 1.98. So it's strange to see the Macs doing so poorly. (0.545 on a standard boinc client). |
|
Hymay Send message Joined: 15 Jun 06 Posts: 8 Credit: 95,312 RAC: 0 |
I don't want to reopen an old can of worms, but could someone point me to some technical documentation on what exactly the optimized client is? From reading other posts, it sounds like the stock BOINC benchmarks were unfair over on SETI, in that the BOINC benchmark wasn't indicative of the SETI workload being run on a PC with an optimized SETI application, and so there was a disparity. And so it would make sense that the optimized client (which we all now understand does NOT run any of the Rosetta programs which are 99% of your crunch time) would have a benchmark modified to reflect your ability to crunch... SETI... with an optimized SETI client and a benchmark that reflects your machine's ability to run the code optimizations. I don't have any tech doc links, but here is a short, fairly basic synopsis. Boinc created a benchmark to measure the FPU/ALU of a CPU, and they based their point claims off the power a cpu brought to the table in these areas. The original benchmark did not include instructions to use MMX, SSE, or SSE2 instruction sets, all of which can dramatically increase FPU/ALU performance in certain situations. This benchmark is internal to the boinc client, and is completely independant of the project application running it. The benchmark basically became outdated with the modern instruction sets coming online, however it didn't really matter much until SETI actually optimized their project to use SSE, etc. They then had the opposite problem rosetta had, a huge volume of extra work being done that did not scale at all with the original benchmark, or the points awarded. The optimized "clients" (the benchmark is really all that was optimized) were created to actually measure the correct amount of cpu power that was being used. The higher benchmarks increased the credit claims appropriately for that project. All it did was enable the new architectures to use the MMX, SSE, SSE2 in the bench calculation. A different OPT was used for the appropriate cpu (ie, you cannot use a SSE2 opt on a chip that only has MMX, or SSE). The old benchmark became the equivalent of using a stopwatch to time/score Olympic events/races. It was accurate back when it was created, but better measuring tools now exit, digital timers accurate to .xx or .xxx sec, stop frame photos/filming, etc. |
|
R.L. Casey Send message Joined: 7 Jun 06 Posts: 91 Credit: 2,728,885 RAC: 0 |
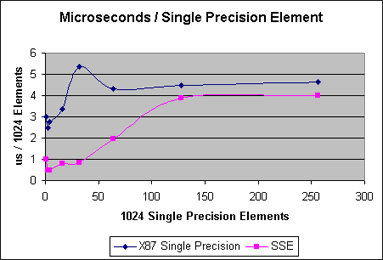
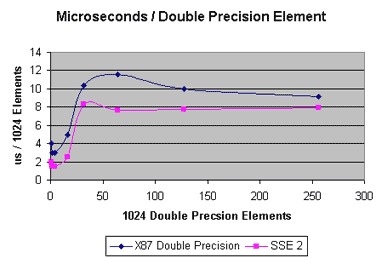
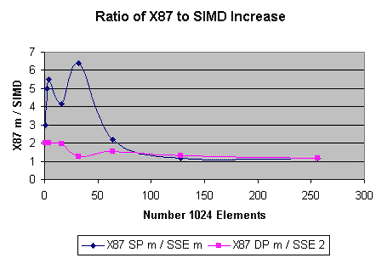
I don't want to reopen an old can of worms, but could someone point me to some technical documentation on what exactly the optimized client is? From reading other posts, it sounds like the stock BOINC benchmarks were unfair over on SETI, in that the BOINC benchmark wasn't indicative of the SETI workload being run on a PC with an optimized SETI application, and so there was a disparity. And so it would make sense that the optimized client (which we all now understand does NOT run any of the Rosetta programs which are 99% of your crunch time) would have a benchmark modified to reflect your ability to crunch... SETI... with an optimized SETI client and a benchmark that reflects your machine's ability to run the code optimizations. ...Hoping not to add fuel to a fire :-) ... The old benchmark became the equivalent of using a stopwatch to time/score Olympic events/races. It was accurate back when it was created, but better measuring tools now exist, digital timers accurate to .xx or .xxx sec, stop frame photos/filming, etc. The "benchmarks" that use some predefined theoretical mix of calculations are "synthetic" in that they don't reflect anything highly useful--a little like "statistics" can be. The Wikipedia has an excellent discussion on benchmarks and Intel provides a thorough discussion of execution time optimization using various generations of their so-call "multimedia extensions", including MMX, SSE, and SSE2. As has been pointed out, the best "benchmark" is a mix of processor instructions that reflects as accurately as possible what actually is executed. For the case of Rosetta, one measure would be a long-term average mix of instructions that the Rosetta Application causes to be executed, if in fact a long-term average exists. Such an average is elusive with Rosetta, it would seem, because the application (including its data-driven components driven by many of the downloaded files) and the targets given to the application are constantly evolving. If the mix of instructions does not converge to a static mix of instructions, then a good alternative seems to be a type of shorter term average that is reflected in the instruction mix now being experienced. As a result, using a measure based on "current" Work Units seems to be ideal. That strategy is the "work-based" approach recently adopted by the Rosetta Project. "Optimality" of the Rosetta application seems to be mostly related to the ability of the application to be modified quickly and cheaply while hunting for better approach to the science. Since exploiting the array-processing extensions to the basic Intel x86/x87 instruction set can be complex--and may not ever be actually applicable except to array processing-intensive applications like SETI that use, for example, Fast Fourier Transforms and the types of problems that are the main target of the extensions--namely, video and audio rendering and conversion, as well as encryption, that are key to improving the end-user experience for many computer users. Intel provids several charts that show the reltive efficiency of the Single-Instruction Multiple-Data (SIMD) "multimedia" extensions: 1. Comparison of Intel x87 and SIMD SSE (Single Precision). 2. Comparison of Intel x87 and SIMD SSE2 (Double Precision). 3. Throughput Improvement Factor of SIMD SSE (SP) & SIMD SSE2 (DP) over the standard x87. The charts show that the amounbt of improvement is quite variable--even when the "application" is completley tuned to the extensions. Chart #3 shows that the improvement with extensions almost disappears for large enough arrays, even if it can be quite good for certain smaller sizes. The upshot of all this is that, as I see it, the project benefits most by (shown in no particular order): 1. Getting tens of thousand of volunteers. 2. Not requiring a quorum of 2 or 3, which effectively divides the science work done per day by the same factor of 2 or 3. 3. Having crunchers increase their comtribution by crunching as much of the time as possible. 4. Having crunchers reduce the amount of processing overhead in their computers by eliminating as many processes and services/daemeons that are not required to crunch, especially for dedicated crunchers. 5. Overclocking or upgrading to increase the basic processor clock rates. Whew! If you've read this far, you are patient! :-) Happy, serene crunching wishes to all! (Edit: BBCode typo) |
|
dgnuff Send message Joined: 1 Nov 05 Posts: 350 Credit: 24,773,605 RAC: 0 |
Does someone have a viewable system that they run 24/7 with a 512 Meg P4 running at 3Ghz with HT off? One with HT On? (With 2 or 3 hour WU run times selected). If you look at my systems, I've got three P4's, two running Linux (Gentoo) one running XP, all of which have HT on. They're all in the 3 GHz range, running 12 hour WU's. I see ABOUT 80 cred per WU, meaning about 320 cred per day (in theory). Which is odd because their RAC's are quite a bit lower (one showing 208 IIRC). Granted they're 1 Gb memory rather than 512 Mb, which for a HT system might be a fair comparison: twice the work - twice the memory? |
|
BennyRop Send message Joined: 17 Dec 05 Posts: 555 Credit: 140,800 RAC: 0 |
http://stats.free-dc.org/new/userstats.php?proj=rah&name=8170 Take a look at the results your machines have turned in over the last month - and the difference between the 7 day average and the RAC. The RAC should approach your 7 day average if it's consistent. |
{kind=link}
{kind=link}
{kind=link}
Message boards :
Number crunching :
Old/New Credit system comparisons

©2026 University of Washington
https://www.bakerlab.org